Paper title: FIND: Human-in-the-Loop Debugging Deep Text Classifiers
Authors: Piyawat Lertvittayakumjorn, Lucia Specia, and Francesca Toni (Department of Computing, Imperial College London)
Venue: The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020)
Paper links: ArXiv (pre-print), ACL Anthology
Contact: Piyawat Lertvittayakumjorn (pl1515 [at] imperial [dot] ac [dot] uk)
Description
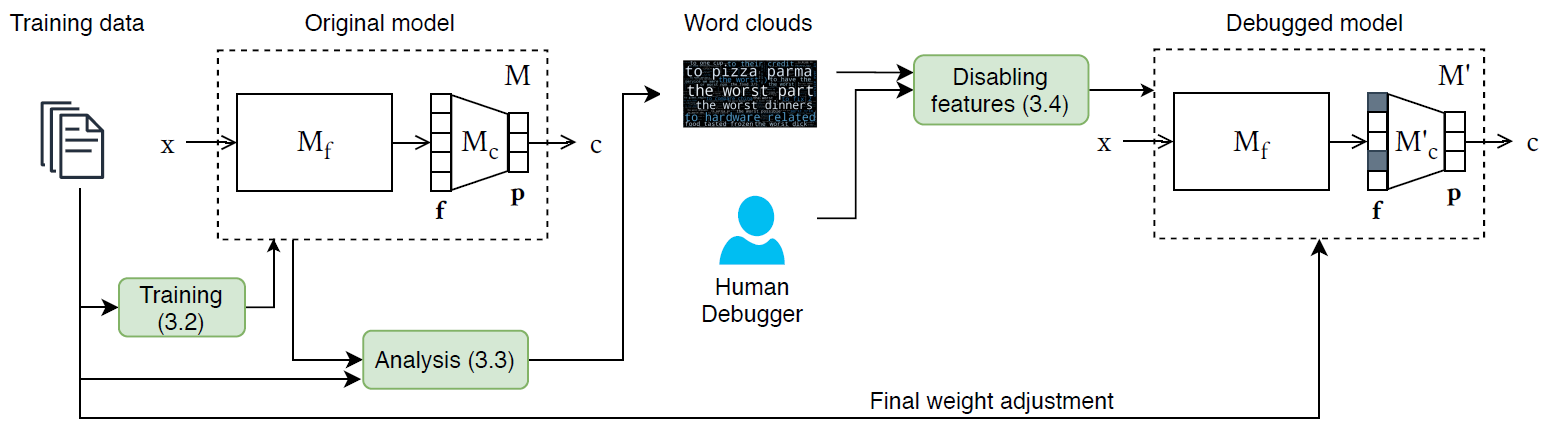 Overview of the debugging framework, FIND. The numbers in the green boxes refer to the
corresponding Sections in the paper.
Overview of the debugging framework, FIND. The numbers in the green boxes refer to the
corresponding Sections in the paper.
FIND (Feature Investigation aNd Disabling) is a framework for debugging deep text classifiers with human-in-the-loop (as shown in the above figure). Generally, deep text classifiers (M) can be divided into two parts.
- The first part (Mf) performs feature extraction, transforming an input text into a dense vector (i.e., a feature vector f) which represents the input. There are several alternatives to implement this part such as using convolutional layers, recurrent layers, and transformer layers.
- The second part (Mc) performs classification passing the feature vector through a dense layer with softmax activation to get predicted probability of the classes.
As the full name suggests, FIND debugs a deep text classifier by allowing humans to (i) investigate the patterns which each learned feature detects or focuses on (using layerwise relevance propagation and word clouds) and then (ii) disable features that are irrelevant or harmful to the classification task (by not using them in the second part of the model). After the features are disabled, the model needs to be fine-tuned on the original dataset again to fully exploit the remaining features.
Currently, FIND in this repository supports 1D Convolutional neural networks (1D CNNs) (Kim, 2014). We provide two jupyter notebook examples (debugging_20Newsgroups.ipynb and debugging_biosbias.ipynb in which you may use FIND together with your judgements to debug CNNs. In the future, we plan to support bidirectional LSTMs and possibly some recent transformer-based models.
Requirements
- Python 3.6
- Standard machine learning and deep learning modules
- tensorflow==1.15.0
- keras==2.2.4
- numpy==1.18.4
- scikit-learn==0.21.3
- Interpretability, visualization, and interaction modules
- matplotlib==3.2.1
- innvestigate==1.0.8
- wordcloud==1.7.0
- ipywidgets==7.5.1
- NLP module and word embeddings
Note that the packages with slightly different versions might work as well.
Datasets
The datasets used in this paper can be downloaded here as a single zip file. Some of the datasets are already in this github repository under the preprocessed_data folder with the data structure. For the other datasets, please download and extract the zip file and put them together in the preprocessed_data folder.
| Experiment | Dataset | #Classes | Train / Dev / Test |
|---|---|---|---|
| 1 | Yelp | 2 | 500 / 100 / 38000 |
| Amazon Products | 4 | 100 / 100 / 20000 | |
| 2 | Biosbias | 2 | 3832 / 1277 / 1278 |
| Waseem | 2 | 10144 / 3381 / 3382 | |
| Wikitoxic | 2 | - / - / 18965 | |
| 3 | 20Newsgroups | 2 | 863 / 216 / 717 |
| Religion | 2 | - / - / 1819 | |
| Amazon Clothes | 2 | 3000 / 300 / 10000 | |
| Amazon Music | 2 | - / - / 8302 | |
| Amazon Mixed | 2 | - / - / 100000 |
Results
The following pages show word clouds (or, literally, n-gram clouds) of the CNN models we experimented on in the paper. If you want to use the original trained models in the experiments, please contact Piyawat (pl1515 [at] imperial [dot] ac [dot] uk). You can then follow the jupyter notebook load_and_run.ipynb as an example to load and run a pre-trained model.
- Experiment 1: Yelp
- Experiment 1: Amazon Products
- Experiment 2: Biosbias
- Experiment 2: Waseem
- Experiment 3: 20Newsgroups
- Experiment 3: Amazon Clothes
Paper
Title: FIND: Human-in-the-Loop Debugging Deep Text Classifiers
Authors: Piyawat Lertvittayakumjorn, Lucia Specia, and Francesca Toni
Venue: The 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP 2020)
Abstract: Since obtaining a perfect training dataset (i.e., a dataset which is considerably large, unbiased, and well-representative of unseen cases) is hardly possible, many real-world text classifiers are trained on the available, yet imperfect, datasets. These classifiers are thus likely to have undesirable properties. For instance, they may have biases against some sub-populations or may not work effectively in the wild due to overfitting. In this paper, we propose FIND – a framework which enables humans to debug deep learning text classifiers by disabling irrelevant hidden features. Experiments show that by using FIND, humans can improve CNN text classifiers which were trained under different types of imperfect datasets (including datasets with biases and datasets with dissimilar train-test distributions).
Paper links: ArXiv (pre-print), ACL Anthology
Please cite:
@inproceedings{lertvittayakumjorn-etal-2020-find,
title = "{FIND}: {H}uman-in-the-{L}oop {D}ebugging {D}eep {T}ext {C}lassifiers",
author = "Lertvittayakumjorn, Piyawat and
Specia, Lucia and
Toni, Francesca",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.24",
pages = "332--348",
}